A Bayesian theory for the estimation of biodiversity
Università of Milano-Bicocca
2026-06-09
Warm thanks (statistical team)

Ching-Lung Hsu
(Duke University)

Alessandro Zito
(Harvard School of Public Health)

David Dunson
(Duke University)
Warm thanks (ecological team, and more…)

Otso Ovaskainen
(University of Jyväskylä)

Tomas Roslin
(University of Helsinki)

International BARCODE OF LIFE
- …and Niittynen, P., Hebert, P. D. N., Zakharov, E., Ratnasingham, S., and the entire iBOL Consortium!,
A journey into statistical biodiversity

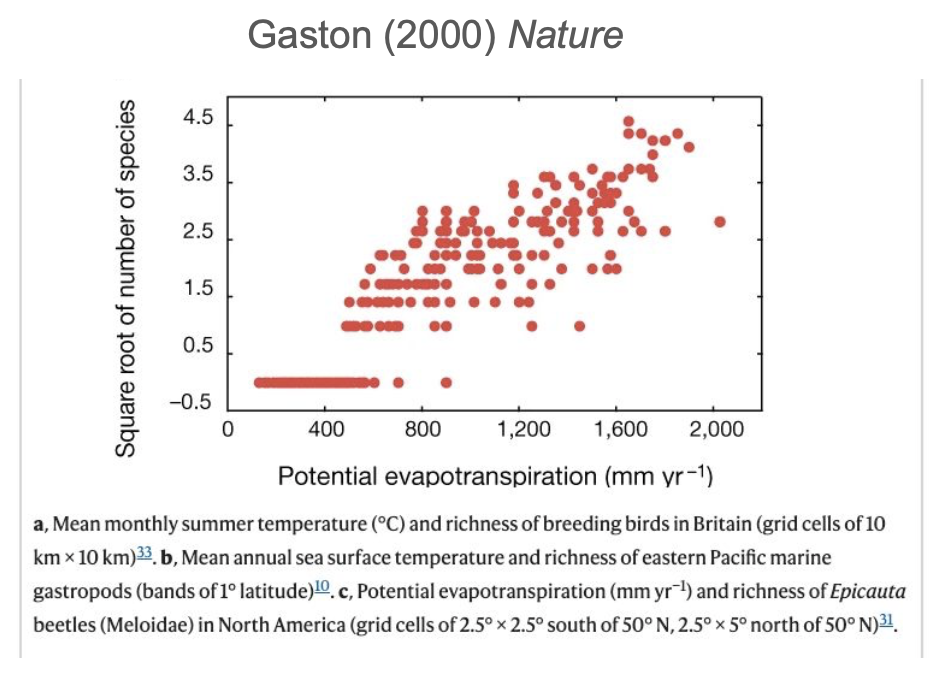
Approximately 80 years ago… Fisher et al. (1943)

Early ideas (Good 1953; Good and Toulmin 1956)

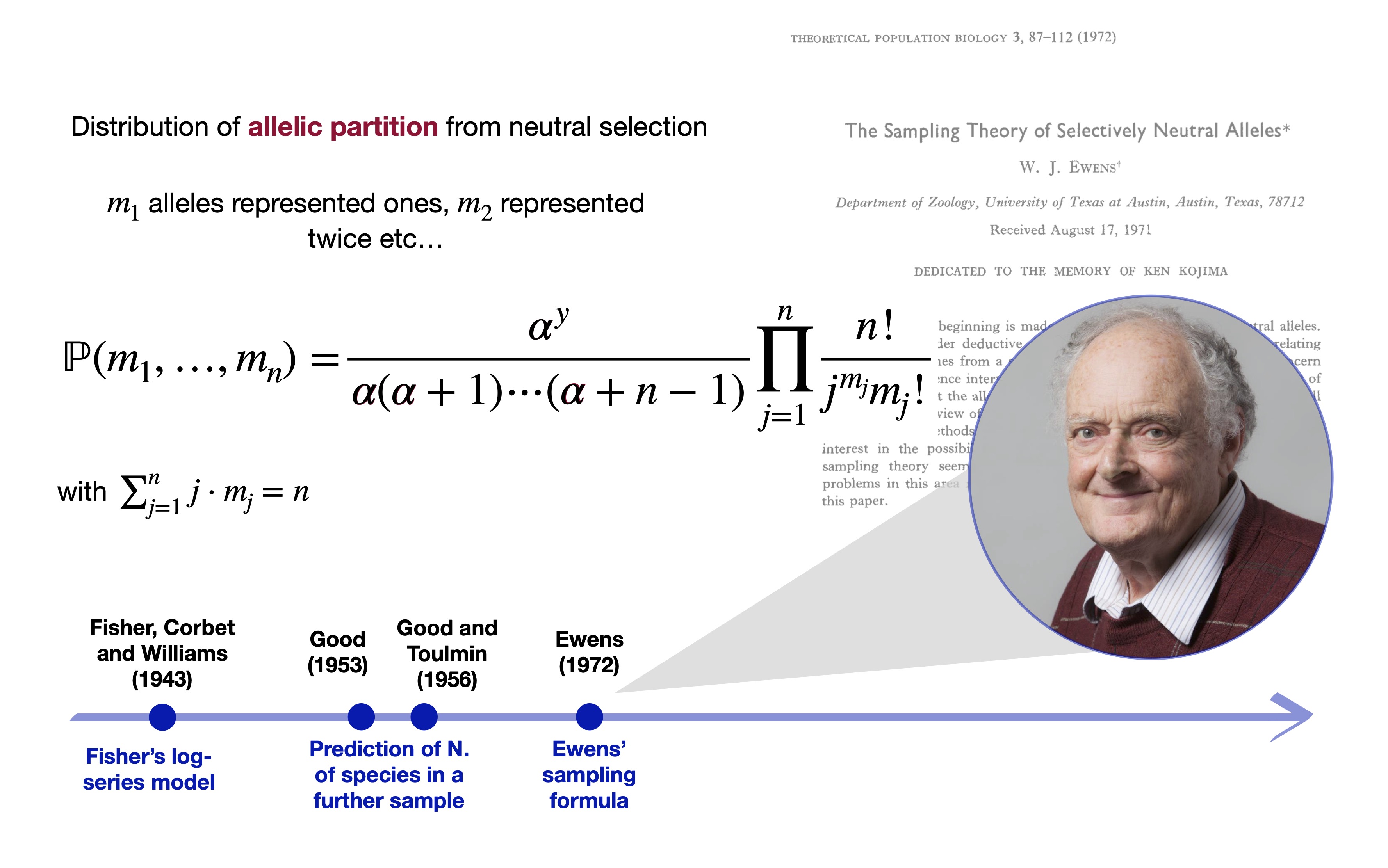
The Ewens sampling formula Ewens (1972)
The Dirichlet process (Ferguson 1973)

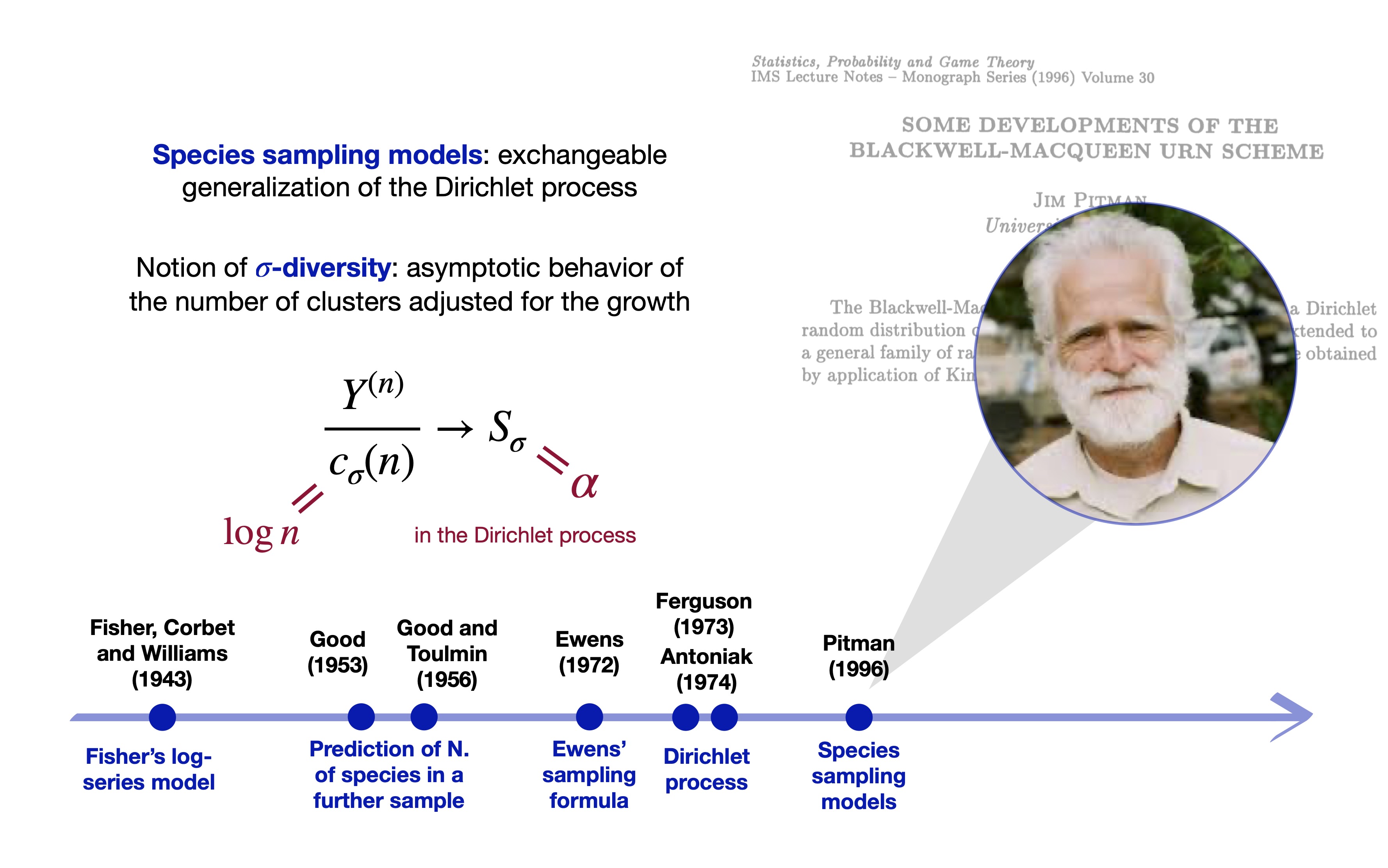
… and species sampling models (Pitman 1996)
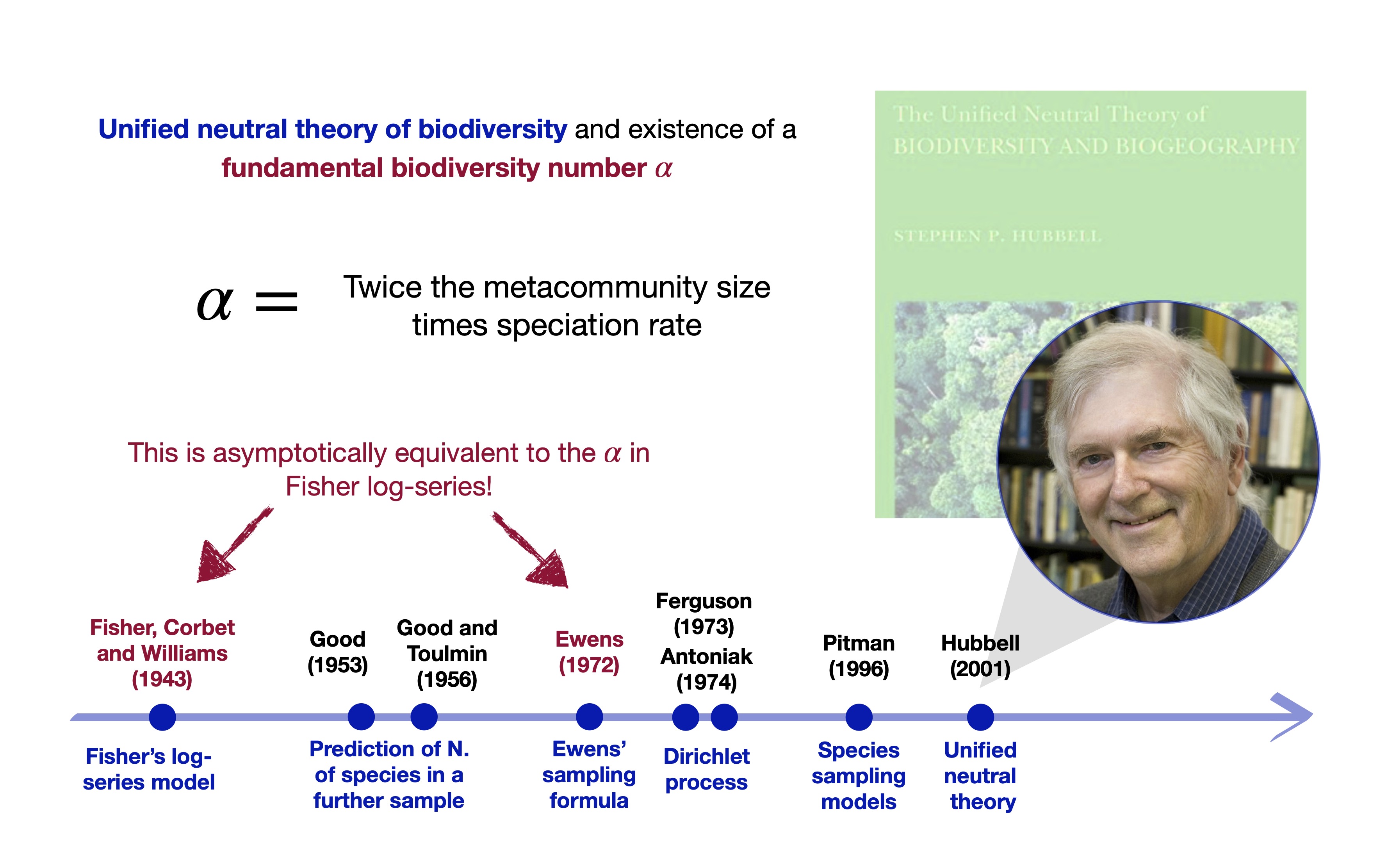
Ewens formula governs the neutral theory! (Hubbell 2001)
All ties together (McCullagh 2016)

Rarefaction and extrapolation
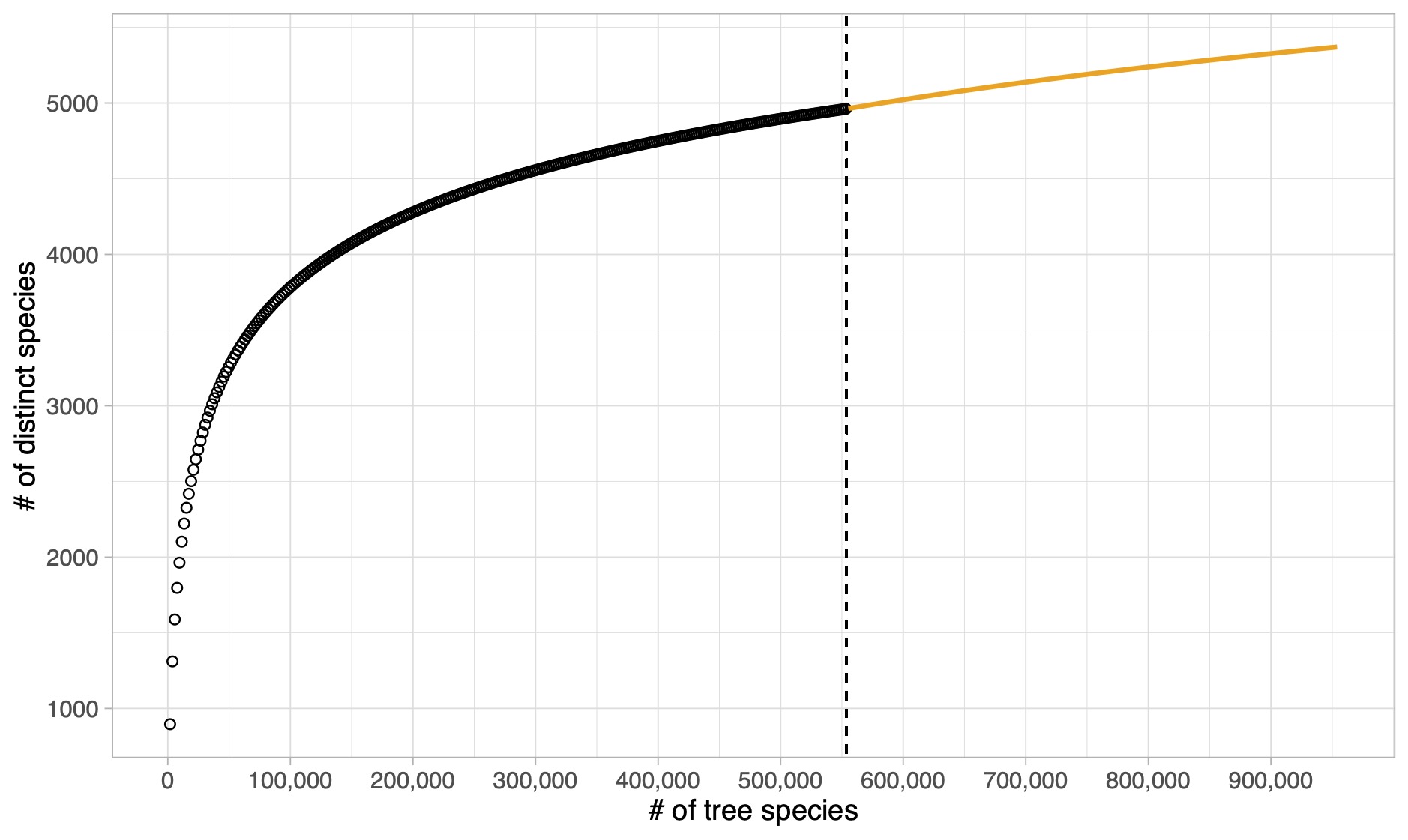
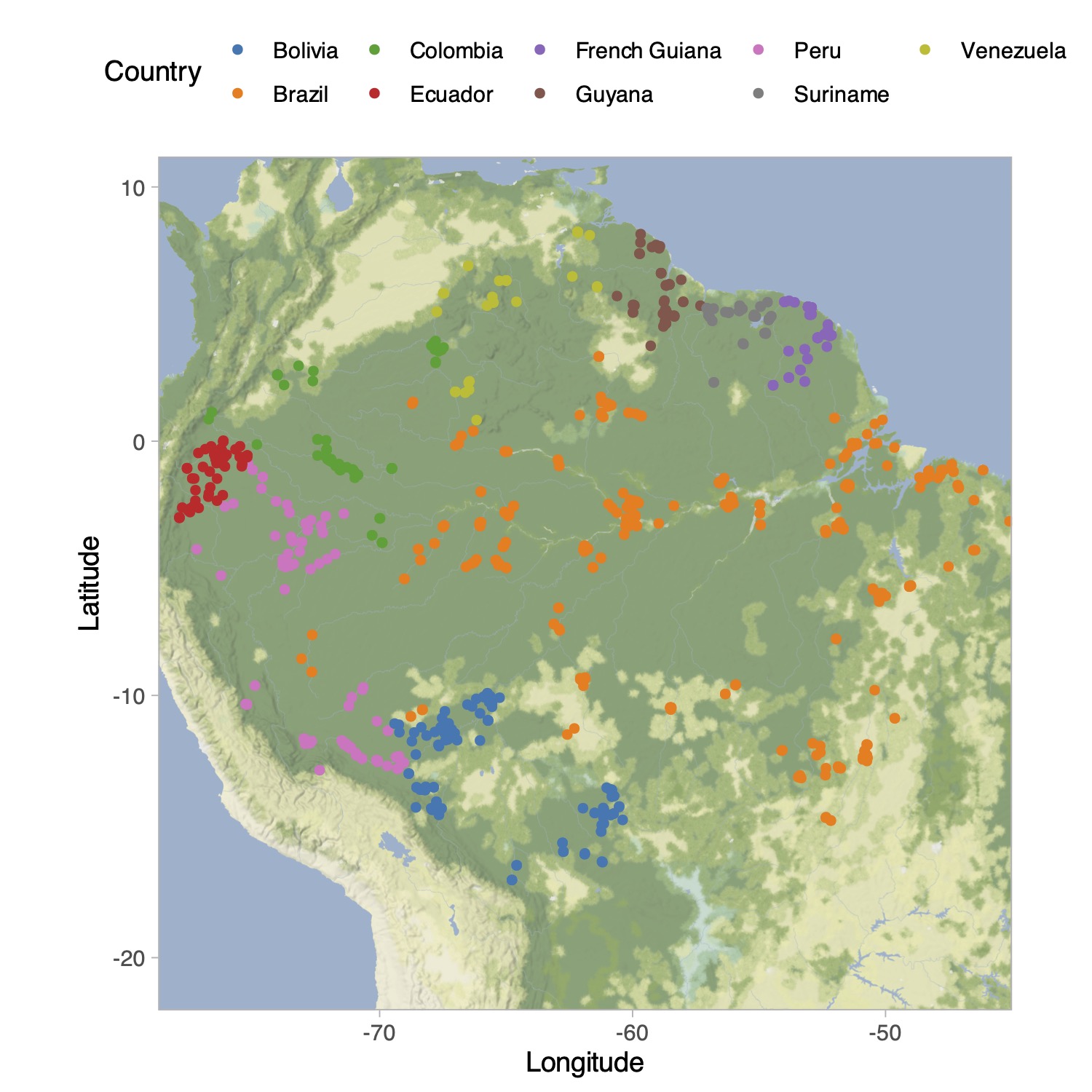
Tree species in the Amazon Basin (Hubbell et al. 2008)
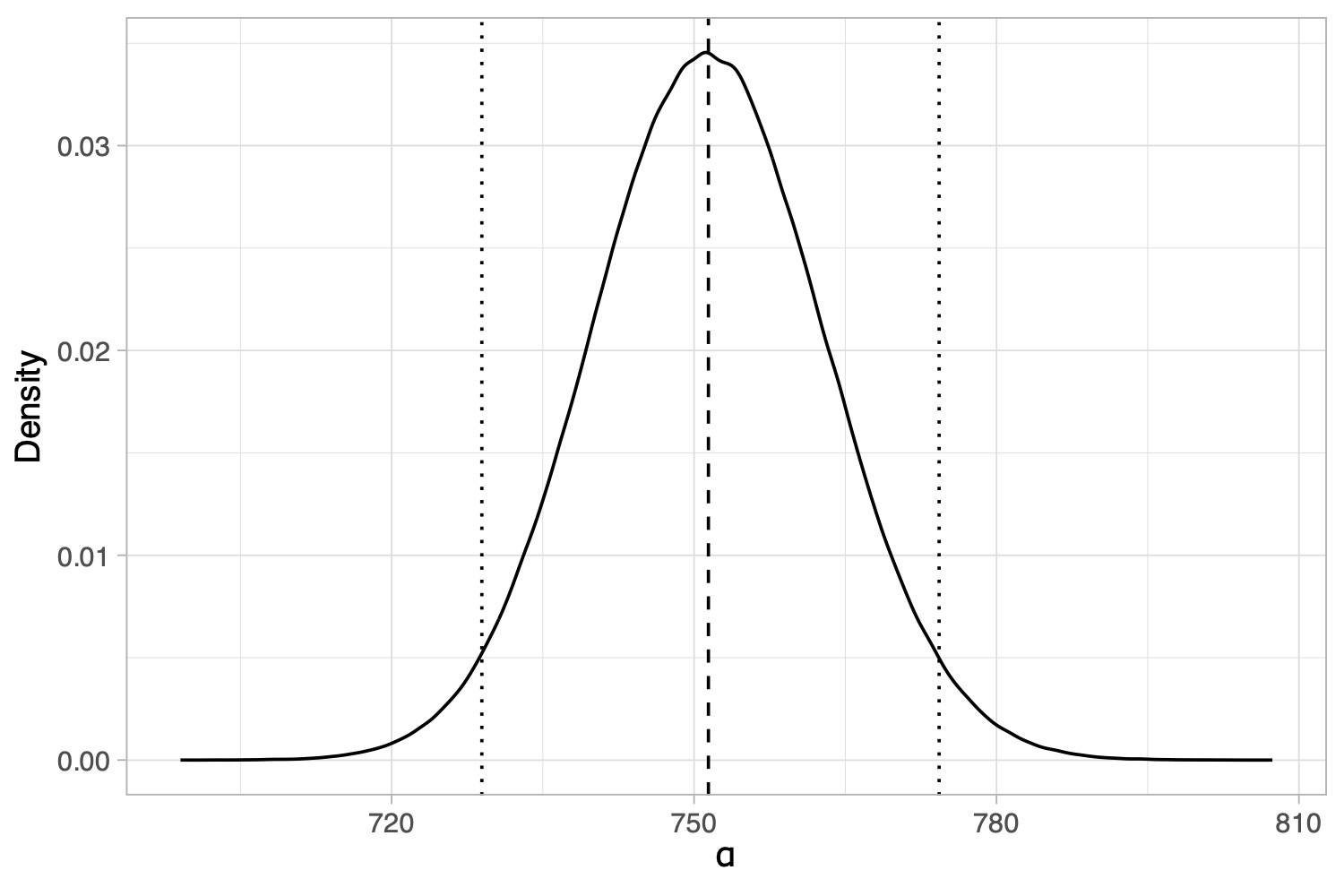
How to get a Bayesian estimator for the biodiversity? We can place a prior on \alpha and the compute its posterior distribution using Bayes theorem.
Posterior distribution of the \sigma-diversity \alpha, under a (conjugate) Stirling-gamma prior (Zito et al. 2024). The dotted lines represent 95% credible intervals. The dashed line is the posterior mean.
Specimens and BINs in Barcode of Life
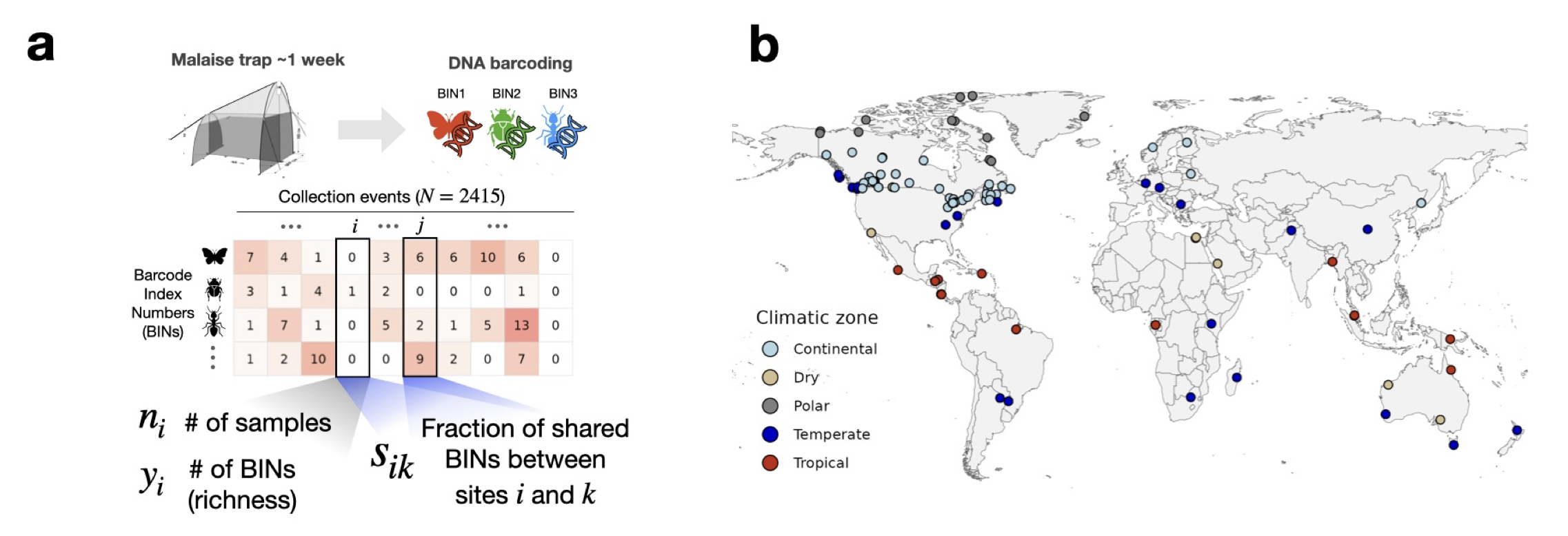
Our data: global Malaise Trap project.
We have a total of 1,781,340 arthropods split across 154,688 BINs and N = 2415 sampling sites.
Beyond the logarithmic growth: non-canonical links
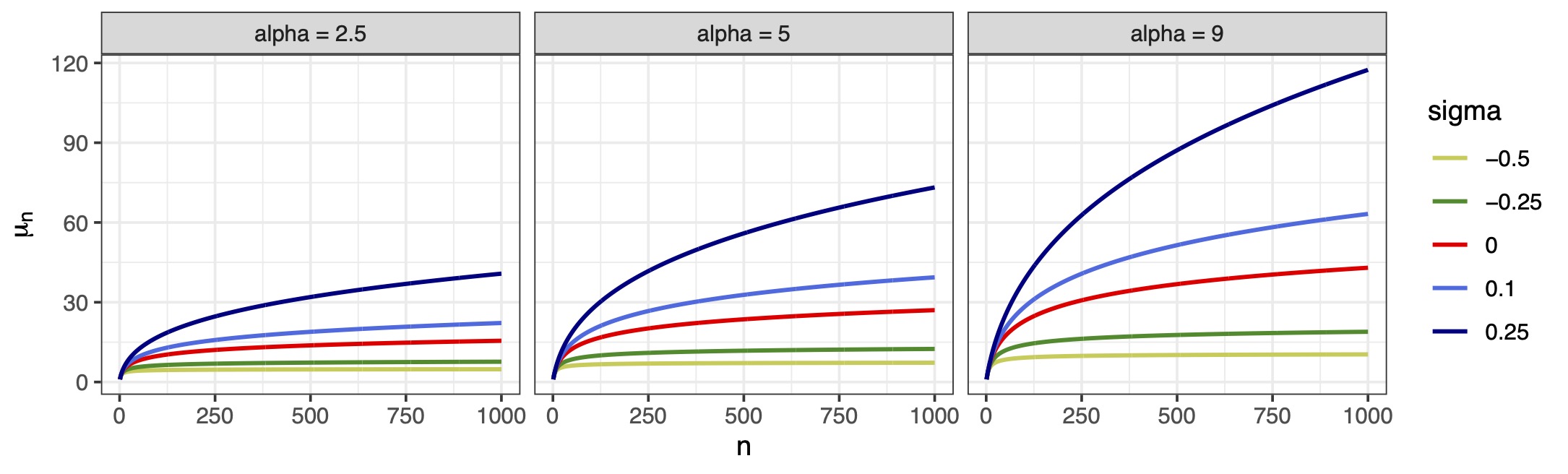
Extensions of the neutral theory of Hubbell (2001) proposes a power-law behavior with a dispersal limitation parameter \omega \ge 0 so that \mathbb{E}\left(Y_i^{(n)}\right) = \sum_{j = 0}^{n_i-1} j^{-\omega} \frac{\alpha_i}{\alpha_i + j}.
Our proposal: a flexible growth depending on \sigma < 1 via non-canonical link \mu_i = \mu(\bm{x}_i^\top\bm{\beta}, n_i, \sigma) = \sum_{j = 0}^{n_i-1} \frac{e^{\bm{x}_i^\top\bm{\beta}}}{e^{\bm{x}_i^\top\bm{\beta}} + j^{1-\sigma}} = g^{-1}(\bm{x}_i^\top\bm{\beta}, n_i, \sigma), \qquad \sigma < 1. The parameter \sigma plays the same role it has in Gibbs-type priors.
Our scientific questions
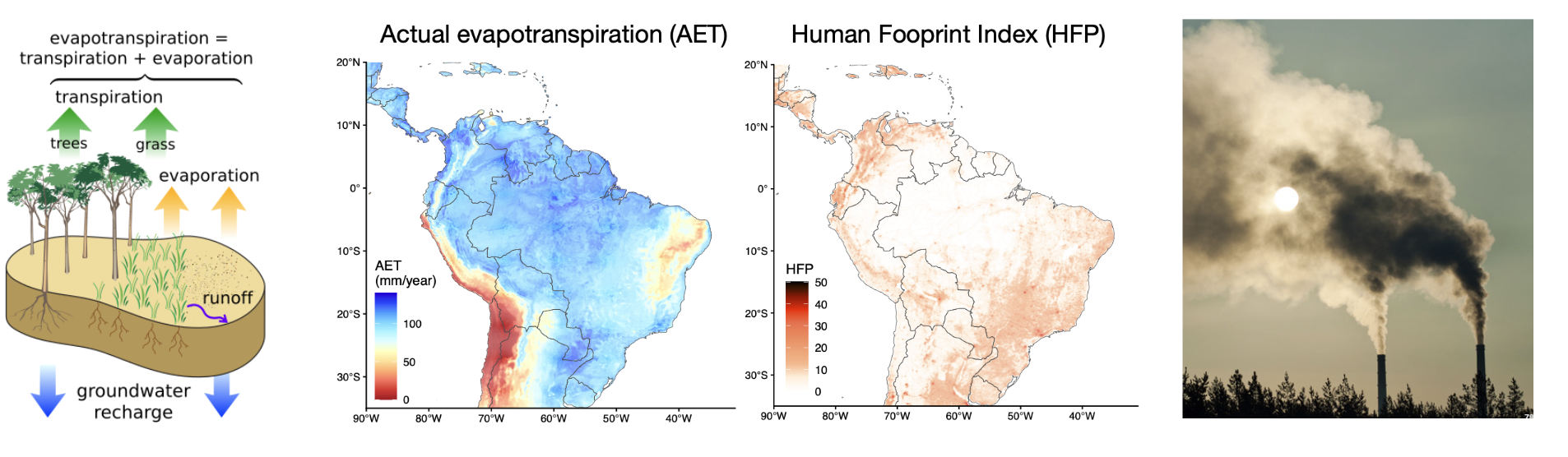
Is (actual) evapotranspiration the main driver of diversity?
How does anthropogenic impact affect diversity?
Hubbell achieves the best predictive performance
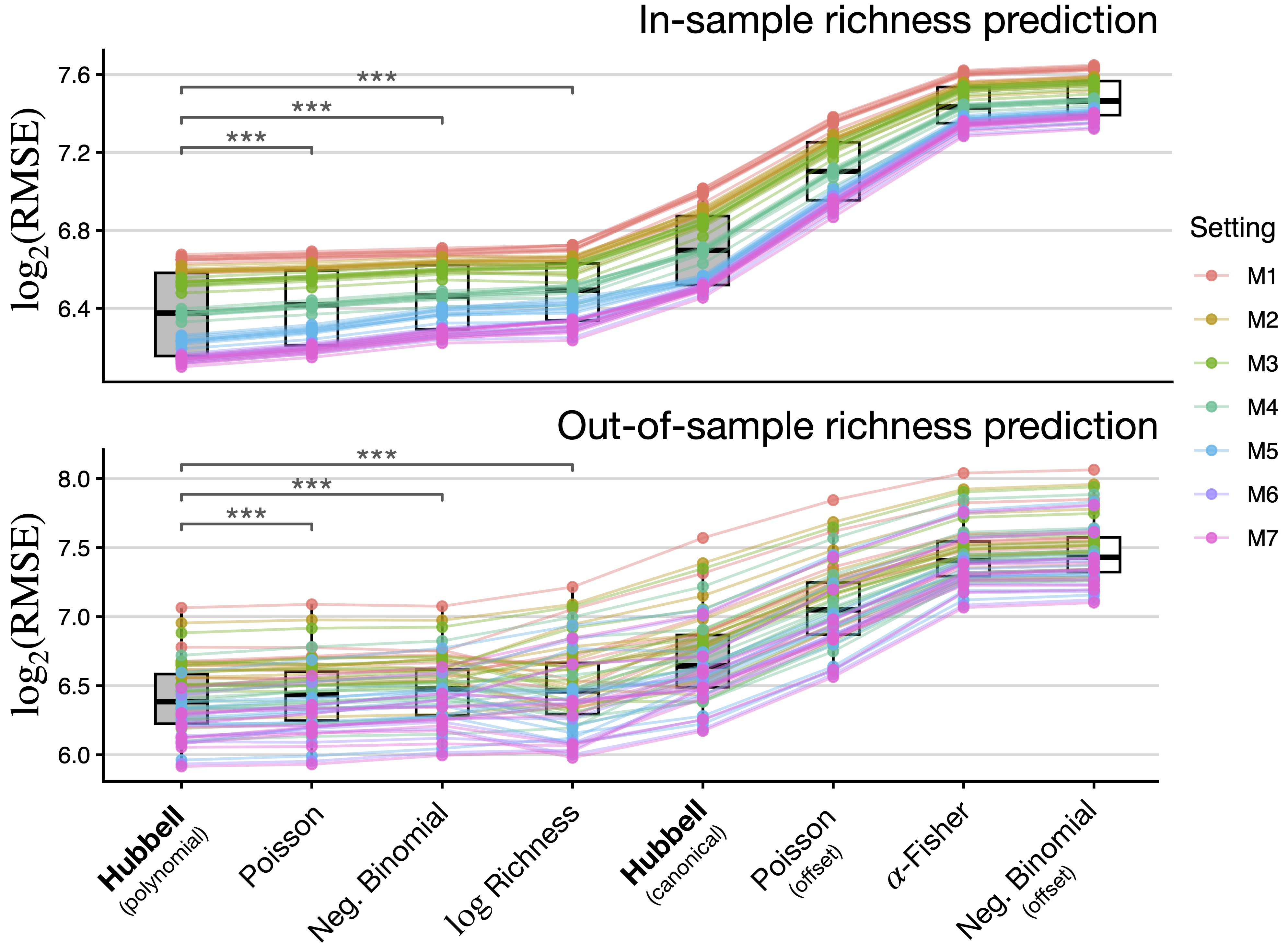
We run a 10-fold cross-validation experiment. Our benchmarks are other GLMs (matching the growth rate with n).
For each nested specification, we split the data into 10 folds, train all models in 90% of the data and predict the remaining 10% (cycle through).
Key results
Model M0: \sigma is estimated as 0.562. Square root!
Model M1:
AETexplains nearly 30% of the total variation in species richnessModel M7:
- A 10 mm/year increase in
AETleads to a 12.4\% increase in diversity on average (\beta = 0.012; P < 0.0001). - A 5 units on the
HFPscale is associated with a 6.1\% reduction in diversity in tropical areas (\beta = −0.013; P < 0.0001), and a 7.5\% reduction in dry zones (\beta = −0.016; P < 0.004) - Polar areas show an interesting increase of 8.2\% (\beta = 0.016; P < 0.038)
- No detected effect in continental areas
- A 10 mm/year increase in
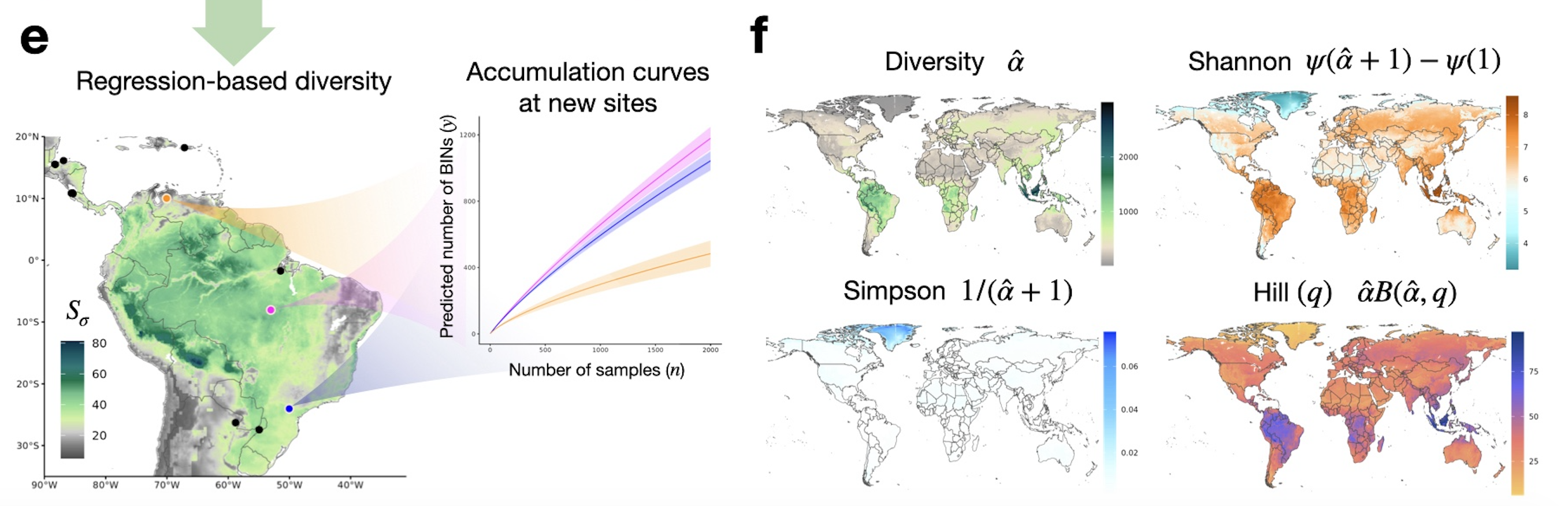
Effects for all diversity indices: variations
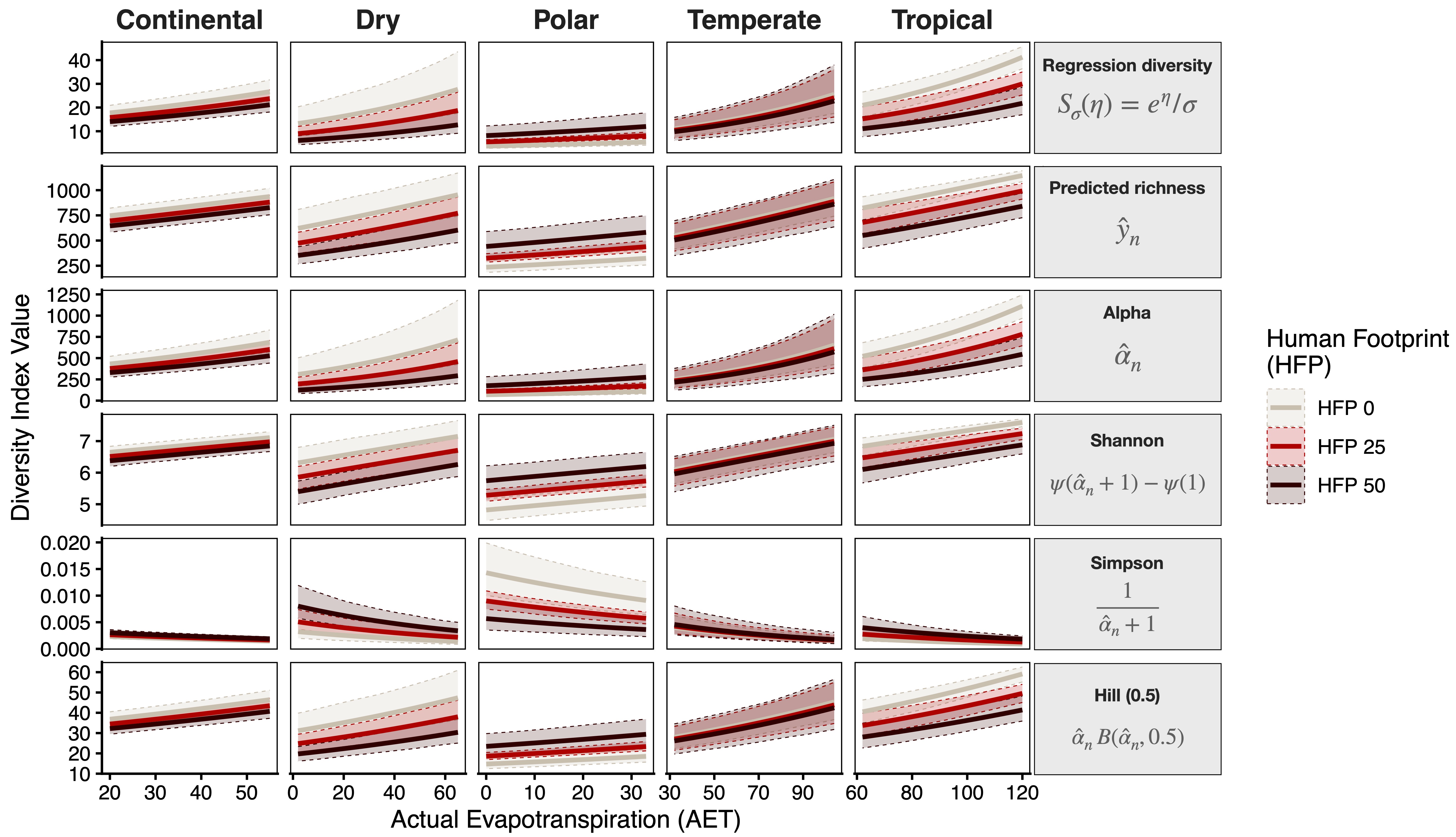
Effects for all diversity indices: global scales
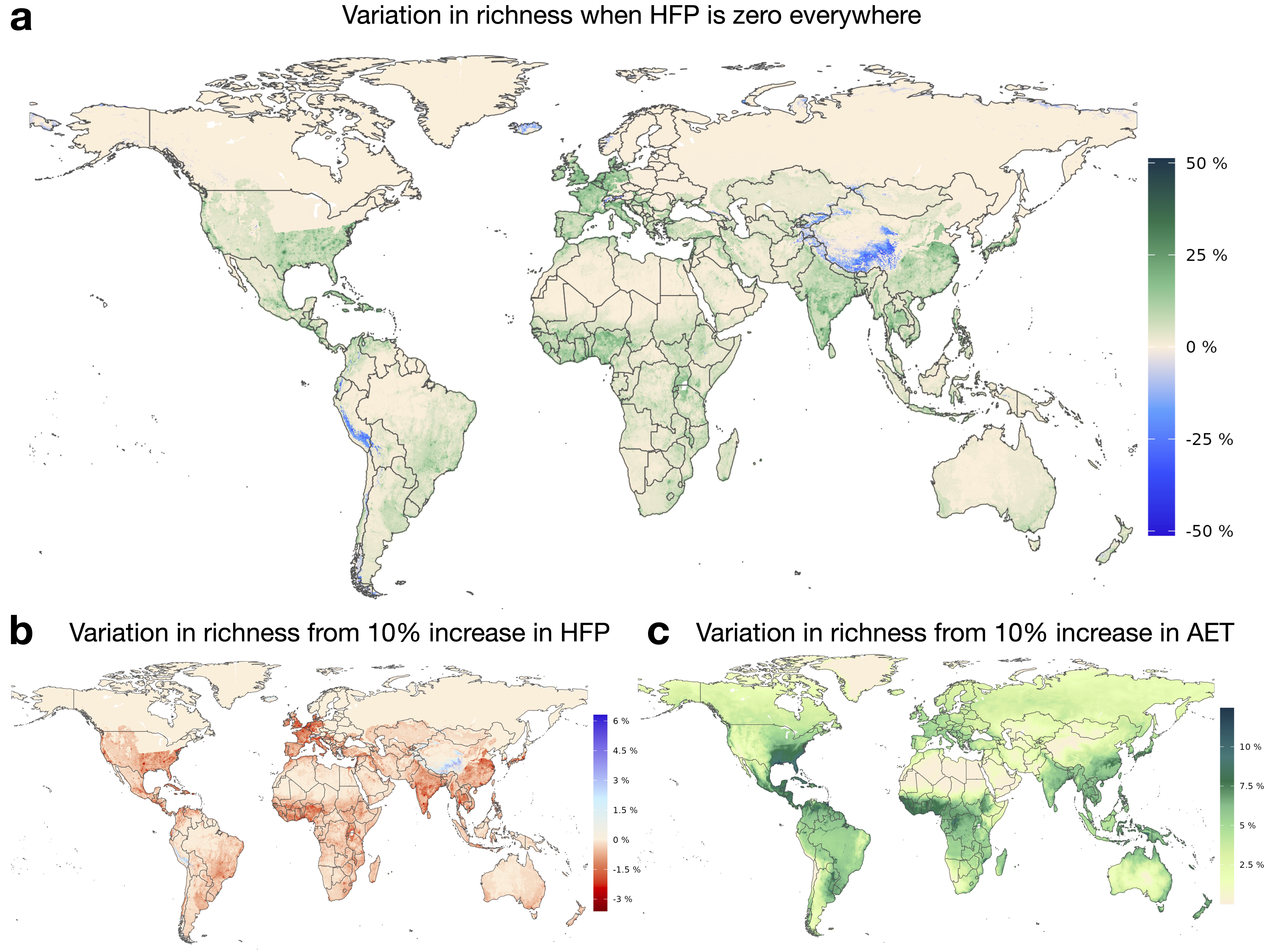
Scenario evaluation
A 5‑unit intensification of human presence globally leads to up to an 8\% reduction in potential richness
A 10\% increase in
AETis associated with an average 3.81\% increase in potential richness.
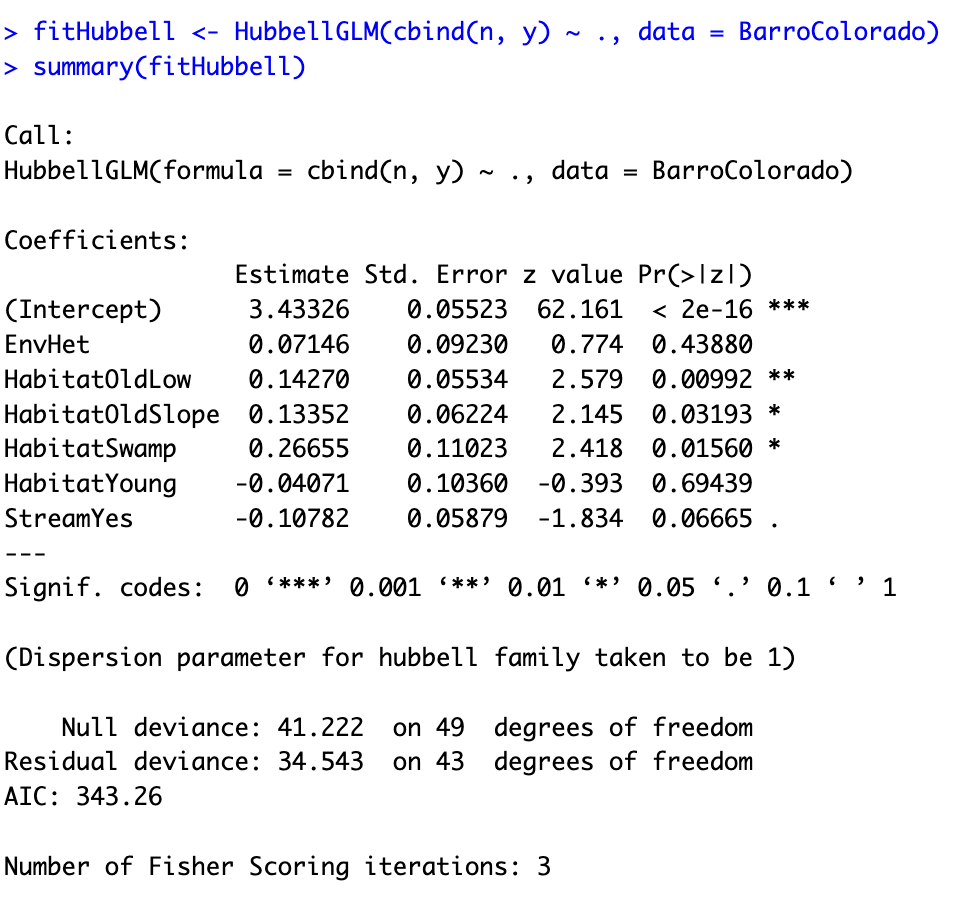
Software: the R package HubbellGLM

Hubbell regression paper available on biorXiv


